| GridMPI™ | ||
| A Project of the Grid Technology Research Center, AIST | ||
Curret Release: GridMPI-2.1.3
Introduction to GridMPI
GridMPI is a new open-source free-software implementation of the standard MPI (Message Passing Interface) library designed for the Grid. GridMPI enables unmodified applications to run on cluster computers distributed across the Grid environment.
GridMPI team found that it is feasible to connect cluster computers and to run ordinary scientific applications in distance upto 500 miles. Simple experiment has shown that most MPI benchmarks scale fine upto 20 millisecond round-trip latency which corresponds to about 500 miles in distance, when the clusters are connected by fast 1 to 10 Gbps networks. 500 miles covers the major cities between Tokyo--Osaka in Japan. Thus, applications which are too large to run on a local cluster should run on multiple clusters in the Grid environment with acceptable performance. However, it is only feasible when using an efficient MPI implementation [1]. Existing implementations are not efficient enough mainly because of the two reasons: their focus on security features and TCP performance problems.
GridMPI skips security layers assuming dedicated secure links. The institutes housing large clusters tend to have their own networks to connect to other institutes in most cases. GridMPI so focuses on the performance on TCP. Since existing implementations are in most cases designed for MPP machines and recently clusters with special hardware, their performance on TCP with Ethernet is not optimal. Also TCP performance itself is not optimal for the work load of the MPI traffic. In addition, support for heterogeneous combinations of computers of the existing MPI implementations is not satisfactory. Thus, GridMPI is designed and implemented from the scratch. GridMPI is carefully coded and tested with heterogeneity in mind.
Overview of the GridMPI
GridMPI targets to a metropolitan-area, high-bandwidth environment (e.g., ≤20ms RTT latency, and ≥10Gbps bandwidth). Improving TCP/IP performance is the key to the successful deployment to the Grid, and GridMPI integrates the PSPacer module to achieve better use of the network. GridMPI runtime notifies to the PSPacer module about the estimated traffic at start and end of collective communications, and the PSPacer module regulated the traffic to adapt the TCP/IP behavior to large number of streams. Currently, GridMPI does nothing about security itself for efficiency reasons, but GridMPI is designed to collaborate with the tools from the NAREGI project for "Grid-level" security.
Features:
- Full conformance to the standard: GridMPI passes 100% of the functional tests of the large test suites from ANL and Intel (MPI-1.2 level).
- Full heterogeneity support: GridMPI is fully tested with combinations of processors of 32bit/64bit and big/little-endian.
- Primary support of TCP/IP and sockets: GridMPI is written from scratch and it is new and clean. It is efficient with sockets, and thus suitable for the Grid as well as ordinary Ethernet-based clusters.
- Cooperation with Grid job submission: GridMPI can be used with Globus, Unicore, tool from NAREGI project, etc.
- Checkpointing support: GridMPI supports checkpointing on Linux/IA32 platforms to restart long-running applications from failure.
- Vendor MPI support: GridMPI supports IBM-MPI, Fujitsu-Solaris-MPI, Intel-MPI, and any MPICH-based MPI for clusters with special communication hardware.
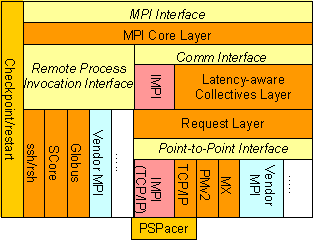
GridMPI is a new MPI programming environment designed to efficiently run MPI applications in the Grid. GridMPI introduces a Latency-aware Collectives layer which optimizes the communication performance over the links with non-uniform latency and bandwidth and hides the details of the lower-level communication libraries.
|
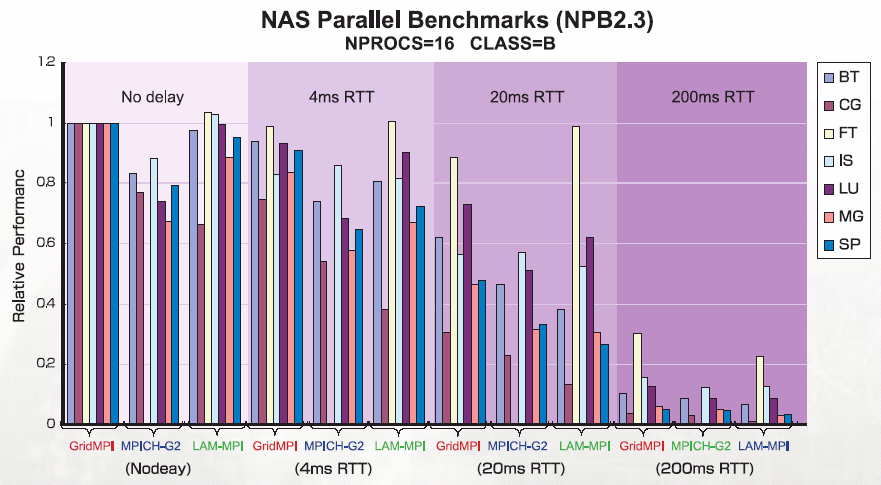
Performance of the GridMPI Version 0.2
To validate the performance of MPI applications in high latency environment, comparison of benchmarks is performed. The graph shows the performance comparison of MPI implementations running NPB2.3 (NAS Parallel Benchmarks). The setting is an emulated WAN environment, where two 8 node clusters are connected through a WAN emulator. The used WAN emulator varies the latency and bandwidth between the clusters, and can simulate behaviour of typical Internet routers. In the experiment, only the latency is varied and the bandwidth is fixed to 1 Gpbs.
|
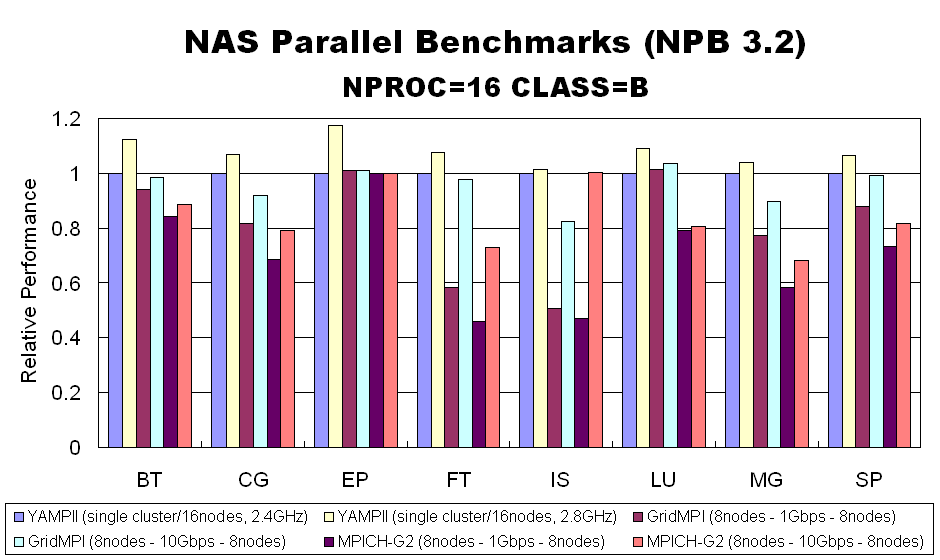
Performance of the GridMPI Version 0.11
To validate the performance of MPI applications in high-speed network environment, the experiment is performed using NPB 3.2 (NAS Parallel Benchmarks). The graph shows the relative performance between single 16 node cluster and two 8 node clusters which are connected through the JGN2 (Japan Gigabit Network 2) network. In the experiment, one cluster is comprised of Pentium4/2.4GHz PCs and the other is comprised of Pentium4/2.8GHz PCs. Redhat Linux 9.0 (kernel 2.4.32) is running on both the clusters. These clusters are about 60 kilometers apart; the network bandwidth is 10 Gbps and the round-trip latency is 1.5 ms, on average. To change the bandwidth between clusters, we employed two 10GbE switches (Huawei 3COM S5648) or two 1GbE switches (Dell PowerConnect 5224). The result shows if the inter-cluster bandwidth is large enough, GridMPI achieves the performance more than 80% of single cluster.
|
($Date: 2007-11-09 10:52:29 $)